概率与期望学习笔记
最后更新时间:
文章总字数:
预计阅读时间:
学一遍不会一遍,遂决定写篇博客把东西记下来。
主要还是记录怎么做题。
定义与性质
这一部分还是详见OI Wiki吧。
常见方法
定义法
对于一些题目来说,我们只需要根据期望的定义 ,把期望转化为求概率,再把概率转化为数数,然后再想办法怎么计数即可。
还有一种方法就是用 来得到期望。
因为这种题目的难点都不在期望,只是套了个期望的壳子而已,所以我一般把这种题称作“假期望题”。
这种题目还挺多,例如最近做的几道:
纯粹的弹幕地狱:难点在后面的计数+莫反
不可思议的迷宫:难点在后面的分讨
符卡对决:难点在后面的莫队
不过也是有一些期望题能用定义做的,不过用这个方法做起来会比较麻烦。
但毕竟是定义,所以我一做题就会先想到这个···
期望的线性性
期望的线性性是一个非常好的性质:它让我们能够把贡献拆开分别统计,最后再合起来得到答案。
拆贡献也是一种非常常见且重要的思想。
DP
虽然说是 DP,但也有很多种状态设计。
例如:正推,逆推等。
在有关概率与期望的 DP 中,可以把每个状态看成一个节点,然后把 DP 的转移看成图上走路,这样会很好理解(事实上很多 DP 都能这么考虑吧)。
例题
下面我用例题带大家感受上面的方法应该如何运用。
绿豆蛙的归宿
方法一:利用期望的线性性
因为要求路径期望总长度,所以可以把路径拆成边,那么就要求每条边产生的期望贡献之和。
一条边产生的贡献的期望,根据期望的定义,等于这条边被经过的概率乘上边权。
所以只需要求每条边被经过的概率即可。
这里有一个套路:算边被经过的概率转化为求点被经过的概率。
设 表示点 被经过的概率, 表示点 的出度,若存在有向边 ,则
那么边 被经过的概率为 。
答案就是把每条边的贡献的期望值加起来。
1 | |
方法二:DP
正推和逆推都是可以的,这里讲逆推。
设 表示从 到 的路径期望总长度,若存在有向边 ,则转移为
因为转移是 向 贡献,所以要建反图,然后在反图的拓扑序上 DP。
初值为 ,答案为 。
注意:因为建了反图,所以转移里的 也变了。请仔细理解。
1 | |
Beautiful Mirrors
利用这道题介绍期望 DP 的各种 trick。
以下的 为题目中的 。
方法一:正推
设 表示从第一面镜子到第 面镜子都高兴的期望天数。
那么在第 天,有以下两种可能:
- 询问失败,概率为 。代价为 。
- 询问成功,概率为 。代价为 。
根据期望的定义,概率乘代价再求和就是期望。则
移项,整理得
初值为 ,答案为 。
可能有疑问:为什么询问失败的代价为 ?
可以把代价拆开来看。
首先,我们已经到了第 面镜子,说明前 面都没失败,这部分的代价为 。
然后,我们在第 面镜子处进行询问,会花费一天,这部分的代价为 。
最后,因为询问失败,我们回到了第一面镜子。但我们的状态为从第一面镜子到第 面镜子都高兴,所以我们还得从第一面镜子一直问到第 面镜子且保持高兴。这部分的代价为 。
方法二:逆推
设 表示从第 面镜子到最后一面镜子的期望天数。
那么在第 天,有以下两种可能:
- 询问失败,概率为 ,我们会回到第一面镜子,代价为 。
- 询问成功,概率为 ,我们会走到下一面镜子,代价为 。
根据期望的定义,概率乘代价再求和就是期望。则
初值为 ,答案为 。
要求 ,但是转移用到了 ,考虑解方程。
如果你把前几项写出来,会发现:
当 时,。
当 时,。
当 时,。
所以:
整理得:
方法三:一种常见的状态设计但是我不知道怎么称呼
设 表示从第 面镜子到第 面镜子的期望天数。
设 ,则
关于代价为什么是这个,可以参考正推。
移项,整理得:
答案为 。
方法四:设一次函数
还是逆推的 DP。
设 ,通过递推求出 ,最后解方程 即可。
[六省联考 2017] 分手是祝愿
一道经典好题。
利用这道题补充期望 DP 的各种 trick。
首先考虑最优操作应该怎么按。
感性理解一下,可以发现:每次按最右边的是最优的。因为除它以外没有数的约数包含它,所以它必须得按。
事实上,这也是唯一的一种按法。证明参考题解。
考虑 DP。
设 表示当前还剩 个键要按的期望操作次数,则转移为:
这应该挺好理解的吧,不再赘述了。
但是这东西没法转移啊,只能高斯消元解方程,怎么办?
方法一:模拟高斯消元
事实上,如果你把系数矩阵写出来,会发现它长这样(图片来自题解):
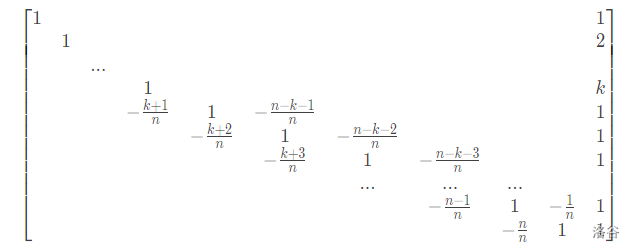
对于这种带状矩阵,有复杂度为 的消元方法。
具体可以参考文章:浅谈高斯消元拓展之 band-matrix。
但高斯消元这东西我学一次忘一次···
方法二:设一次函数
设 ,那么发现 是好求的。
转移为
代入得
发现 被消没了,则
边界为 。
然后用 把 求出来即可。
方法三:一种常见的状态设计
把之前的 DP 扔了,换状态。
设 表示从还剩 个键要按到还剩 个键要按的期望操作步数。
那么还剩 个键时,有以下两种可能:
- 按对了,概率为 ,代价为 。
- 按错了,概率为 ,代价为 。
则转移为
为什么代价是这个?
感觉和之前那个一样吧,但还是再解释一遍:
可以把代价拆开来看。
首先,我们按了一次,代价为 。
然后,因为按错了,所以现在还剩 个键需要按。那么从还剩 个键到还剩 个键的代价为 。
最后,我们需要把还剩 个键变成还剩 个键(因为这是我们的状态),代价为 。
我们先按最优解的操作按一遍,得到操作次数 。那么答案为
[SHOI2002] 百事世界杯之旅
设 表示当前已经拿了 种物品,那么转移为
移项整理得
初值为 ,答案为 。
事实上,你把式子再写一下,会发现 。
Let’s Play Osu!
加强版:OSU!
设 表示以 结尾连续成功长度的期望, 表示以 结尾连续成功长度的平方的期望。
然后根据期望的线性性,。
所以转移为
弱化版答案为 。
加强版答案为 。
[Cnoi2020] 线形生物
期望的线性性好题。
设 表示 到 的期望步数,则 。
设 表示 到 的期望步数, 表示 的返祖边条数, 为 的返祖边集,则
设 ,则
把 都放到左边,整理得
答案为 。
[HNOI2013] 游走
高斯消元经典题。
设 表示点 得期望经过次数, 表示边 的期望经过次数, 表示点 的出度,则
然后高斯消元把 求出来,再用 把 求出来即可。
至于编号,我们只需要贪心的给期望经过次数越大的边编号越小即可。
忽略了很多细节,写的时候需要注意。
Broken robot
也是高斯消元经典题。
设 表示从 走到最后一行的期望步数,转移为
初始值为 。
因为只能往下走,所以行没有后效性,但列有后效性。
所以从下往上消元即可。
暴力消元复杂度不对,但是你把系数矩阵写出来,发现又是带状矩阵。
所以按之前的方法消元就行了。
[HNOI2015] 亚瑟王
根据期望的线性性,总伤害就是每张卡的伤害乘上该卡的发动概率,所以考虑如何求出每张卡的发动概率。
这道题最难的地方就是轮次,如果根据轮次来 DP 的话,会发现有后效性。例如我一开始想的是 表示第 轮发动 的概率,发现转移不了。
我们换一个思路,既然轮次有后效性,那就不能按轮次 DP 了,而是直接考虑卡牌。
感觉是和荷取融合很像的套路。
设 表示在整局游戏中,前 张牌发动了 张的概率,则转移为
解释一下这个转移。
如果 从 转移来,说明第 张牌在整局游戏中都没有发动。
因为前面已经发动了 张,也就是占用了 轮的机会,所以概率为 。
如果 从 转移来,说明第 张牌发动了。
但发动的概率不好求,考虑用 减去不发动的概率,为 。
那每张卡的发动概率就好求了:
[NOIP2016 提高组] 换教室
感觉比较简单。
设 表示前 节课成功换了 次教室。
转移就是考虑换不换,如果换还要考虑能否成功,乘上最短路长度即可。
是没啥意思的分类讨论,不展开写了。
最短路用 Floyd 预处理即可。